


Meta-Learning Intelligent Exploration: Improving RL Efficiency
- Tech news
- July 31, 2023
- No Comment
- 28
Introduction:
When venturing into new realms, standard reinforcement learning (RL) agents often pale in comparison to humans. Their struggle to intelligently explore domains hampers their learning efficiency. Existing exploration methods, like exhaustive search, are inadequately approximated, limiting their ability to tackle complex tasks. In this article, we shall delve into an innovative solution known as the First-Explore meta-RL framework, which aims to revolutionize exploration efficiency and overall performance.
The Limitations of Standard RL Agents in Exploration:
Standard RL agents exhibit a lack of intelligent exploration capabilities. They fail to consider complex domain priors and previous exploration experiences, and which come naturally to humans, facilitating efficient learning. While approaches such as novelty search or intrinsic motivation attempt to address this issue, so they still fall short in capturing the full spectrum of intelligent exploration strategies required for complex tasks.
The Conflict between Exploration and Exploitation:
A fundamental barrier in RL lies in agents simultaneously attempting to explore and exploit. This dual pursuit often leads to conflicts between the two objectives and hindering the agent’s proficiency in either domain. Resolving this conflict is paramount to unlocking intelligent exploration capabilities in RL.
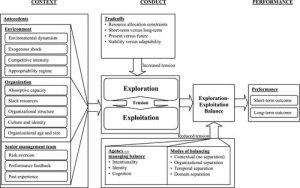
Introducing the First-Explore Meta-RL Framework:
The First-Explore meta-RL framework introduces a promising solution. It involves training two distinct policies: and one for exploration and another for exploitation. By decoupling exploration from exploitation, conflicts are mitigated and allowing for more efficient and effective learning.

Learning Intelligent Exploration Strategies:
With the First-Explore framework, agents can now learn sophisticated exploration strategies and including exhaustive search and more. These strategies empower the agent to efficiently gather crucial environmental information, paving the way for more successful learning experiences.

First-Explore Performance and Advantages:
The results yielded by the First-Explore approach are remarkable. so It surpasses dominant standard RL and meta-RL approaches in domains where exploration necessitates sacrificing immediate rewards. By prioritizing exploration initially and then leveraging the acquired knowledge because the First-Explore framework achieves superior overall performance.

Towards Human-Level Exploration in RL:
The ultimate objective of the First-Explore meta-RL framework is to imbue agents with human-level exploration capabilities. By emulating the way humans intelligently explore novel environments, these agents can adeptly tackle challenging and uncharted exploration domains.
Conclusion:
Incorporating the First-Explore meta-RL framework represents a significant leap towards enhancing the intelligence and efficiency of RL. but By disentangling exploration from exploitation and emphasizing intelligent exploration strategies, this approach empowers agents to excel in complex domains. so As research advances, we may witness RL algorithms capable of attaining human-like exploration prowess and leading to groundbreaking advancements in artificial intelligence and problem-solving prowess.






